网络爬虫
前言
此文仅仅能保证入门,不保证商业生产。文中爬取网站数据为演示所用,仅用于学习和研究
什么是爬虫?
爬虫也被称为网络爬虫或网络蜘蛛,是一种自动化程序,用于在互联网上浏览并收集数据。它们按照一定规则,自动地抓取万维网的信息。爬虫通常从一个或若干个初始网页的URL开始,获取这些网页的内容,然后在这些网页中找到其他网页的URL,并继续抓取这些新网页的内容,如此循环往复,直到满足一定的停止条件为止。这些被爬虫抓取的网页内容可以存储在本地,供后续的数据处理和分析使用。
爬虫的主要目标是自动提取结构化数据,这些数据可能包括文本、图片、视频或其他类型的文件。它们通常用于搜索引擎的索引构建、数据挖掘、价格监测、竞品分析等多种场景。
爬虫的用途
- 搜索引擎:如Google、Baidu等,使用爬虫抓取互联网上的网页内容,并创建索引,以便用户可以快速地搜索和获取信息。
- 价格比较:对于许多购物网站和电子商务平台,爬虫可以抓取商品信息,如价格、描述等,然后整合到一个平台上,方便用户比较不同网站的价格,从而做出更明智的购买决策。
- 社交媒体分析:爬虫可以收集社交媒体平台上的大量数据,包括用户信息、评论、点赞数等,进而进行用户行为分析、情感分析或市场趋势研究。
- 新闻聚合:爬虫能够自动从多个新闻网站上抓取新闻内容,并整合到一个平台上,为用户提供一个方便阅读和获取最新新闻的平台。
- 学术研究:爬虫在学术领域也发挥着重要作用,它可以收集学术论文、研究报告等,为学者提供便捷的资料获取方式。
- 数据收集与分析:爬虫可以用于收集各类数据,包括但不限于招聘信息、股票行情、旅游攻略、音乐资源等,进而进行数据的整理、分析和比较。
- 舆情监控:对于企业而言,爬虫可以帮助其快速收集和分析社会公共事件的相关信息,以进行舆情监控和风险评估。
爬虫基本原理
- 发起HTTP请求
- 解析HTML文本
- 定位并提取文本中的目标数据
- 对目标数据进行清洗处理后存储
网络爬虫是一种自动化收集网络信息的程序。其基本原理是通过发起HTTP请求获取网页的HTML文本,然后通过解析文本后从中查找目标数据并进行提取和清洗处理,然后对数据进行存储
常见网页爬取形式
基于请求库的爬虫
最基本的一种爬取方式,通过发送HTTP请求获取网页内容,然后解析网页数据。这通常适用于静态网页或简单动态网页的爬取。在Java中,可以使用
Apache HttpClient或OkHttp等库来发送HTTP请求。在Python中,可以使用Requests库来发送HTTP请求。使用JavaScript渲染引擎
对于需要JavaScript渲染的网页,即那些内容通过JavaScript动态加载或生成的网页,可以使用支持JavaScript渲染的引擎来模拟浏览器行为并获取完整页面内容。在Java中,可以使用
Selenium或Puppeteer等工具来实现这一点。基于浏览器自动化的爬虫
通过自动化工具如
Selenium或Puppeteer,可以完全模拟浏览器的行为,包括点击、输入等交互操作,进而获取需要登录或具有复杂JavaScript交互的网页数据。使用爬虫框架
一些爬虫框架提供了完整的爬取处理工具链,包括请求发送、数据解析、数据存储等功能。例如,Java中的
WebMagic、cdp4j和Python中的Scrapy都是强大的爬虫框架,它们简化了爬虫的编写和维护过程。API接口爬取
如果目标网站提供了API接口,那么通过API接口爬取数据是最直接和高效的方式。可以通过抓包(
Fiddler、Charles)的方式拿到网站请求然后调用API接口,可以直接获取结构化数据,无需解析HTML或处理JavaScript。使用第三方爬虫工具或服务
市面上有许多第三方爬虫工具或服务,它们提供了易于使用的界面和强大的功能,可以帮助用户快速实现网页爬取。这些工具通常支持多种爬取策略和高级功能,如代理设置、反爬虫机制处理等。
实例演示
本实例基于Java语言使用 cdp4j 库来进行数据爬取演示(因cdp4j原理为模拟谷歌浏览器进行请求渲染,所以使用当前库的前置条件为,系统上必须安装Chrome或Chromium浏览器)。
cdp4j是一个Java库,它提供了高级API来通过DevTools协议控制Chrome或Chromium浏览器。cdp4j的主要功能是自动化基于Chrome或Chromium的浏览器操作,包括自动使用网页和测试网页。这个库具有清晰简洁的API,使开发人员能够执行在浏览器中手动完成的大多数操作,例如生成页面的屏幕截图和PDF,爬网单页应用程序并生成预渲染的内容,自动执行表单提交、UI测试和键盘输入等。
依赖导入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<dependency>
<groupId>io.webfolder</groupId>
<artifactId>cdp4j</artifactId>
<version>3.0.12</version>
</dependency>
<!-- 2.2.1 版本的cdp4j不用导入winp;3.0+ 版本的cdp4j需要导入此包 -->
<dependency>
<groupId>org.jvnet.winp</groupId>
<artifactId>winp</artifactId>
<version>1.28</version>
</dependency>
<!-- HTML解析器 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.1</version>
</dependency>仿官网示例
1
2
3
4
5
6
7
8
9
10
11
12public static void main(String[] args) {
Launcher launcher = new Launcher();
try(SessionFactory factory = launcher.launch();
Session session = factory.create()
){
// 请求当当网
session.navigate("https://search.dangdang.com/?key=java&act=input");
session.waitDocumentReady();
String content = session.getContent();
System.out.println(content);
}
}
上述代码为官网给出的HelloWorld示例,我们尝试将链接改为“当当网”官网链接,取请求Java书籍列表页后拿到页面源码。
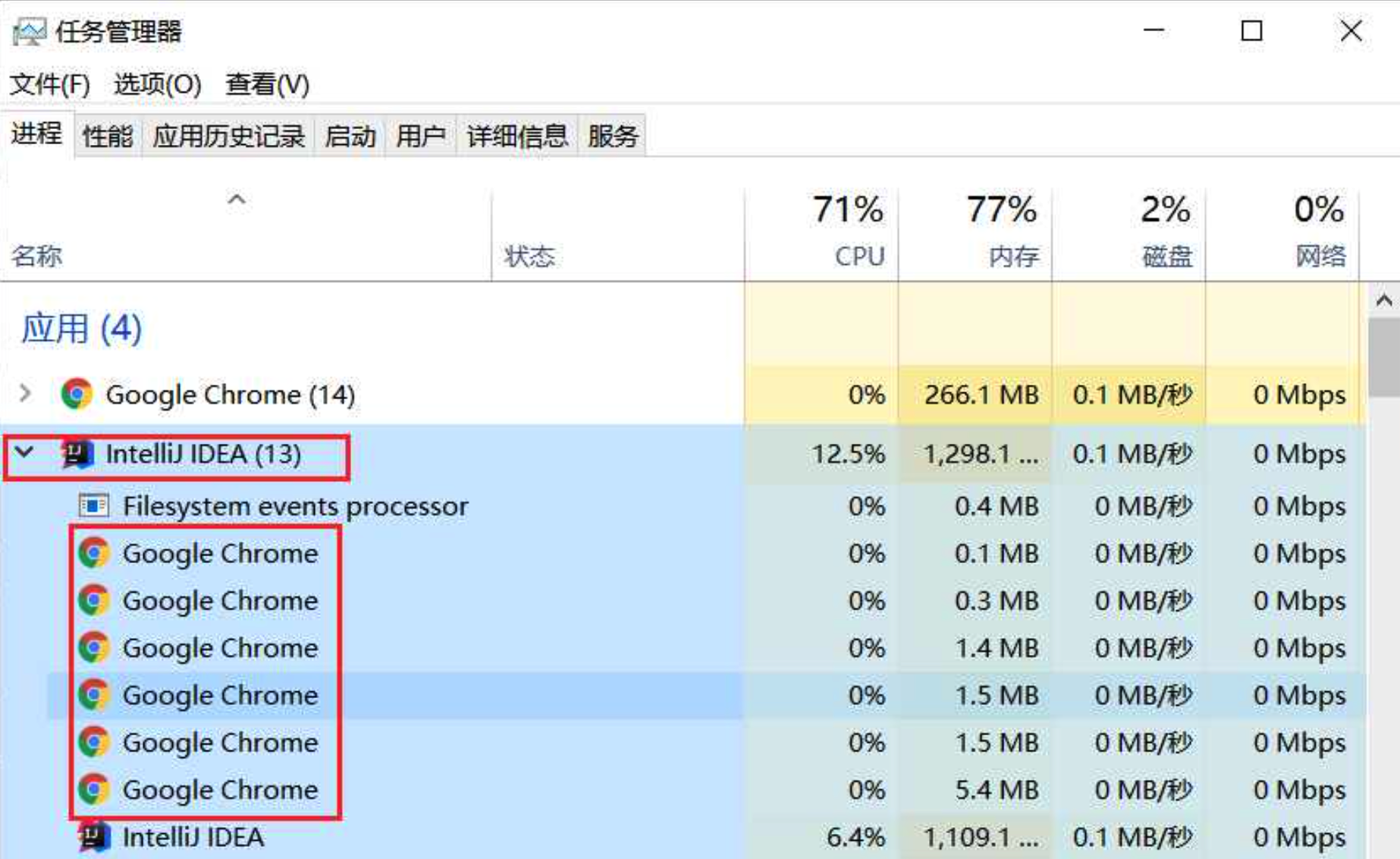
在启动后我们可以看到程序执行过程中会打开一个谷歌浏览器窗口,然后自动填入我们所代码中所写入的链接然后回车请求网页,请求成功后关闭当前网页。通过任务管理员也可看到程序执行中会增加谷歌浏览器后台运行任务(我们可得出结论,cdp4j本质为打开一个新的浏览器窗口去模拟我们代码逻辑中的命令从而去渲染网页后拿取整个网页返回)。
示例调整后解读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public static void main(String[] args) {
// 创建Launcher对象,用于启动和管理Chrome浏览器实例
Launcher launcher = new Launcher();
// 不启用GPU加速,不会弹出浏览器
try (SessionFactory factory = launcher.launch(Arrays.asList("--disable-gpu",
"--headless"))) {
// 创建浏览器上下文
String context = factory.createBrowserContext();
// 创建会话并导航到指定网页
try (Session session = factory.create(context)) {
// 设置要爬的网站链接,示例为请求当当网
session.navigate("https://search.dangdang.com/?key=java&act=input");
// 默认超时时间timeout是10*1000 ms,可手动设置
session.waitDocumentReady(30 * 1000);
// 通过session得到渲染后的html网页内容
String html = session.getContent();
System.out.println(html);
}
// 释放浏览器上下文资源
factory.disposeBrowserContext(context);
}
// 关闭浏览器后台进程
launcher.getProcessManager().kill();
}使用Jsoup解析网页
Jsoup是一个用于处理HTML的Java库。提供了一套简洁省力的API,用于从某个URL,文件或字符串中解析HTML;然后可以使用DOM或CSS选择器来查找、取出数据。我们以解析“当当网”网页为例,通过使用
Jsoup将前面所请求的网页源码转为DOM树结构,然后通过分析DOM元素层级从而去获取我们想要拿取的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// 将获取内容转为DOM树并获取网页body
Element body = Jsoup.parse(html).body();
// 分析DOM树,获取中间书籍信息
Element shopListElement = body.getElementById("component_59");
// 获取整个书籍li集合
Elements bookLiElements = shopListElement.getElementsByTag("li");
// 循环读取每个书籍所在标签
for (Element bookLiElement : bookLiElements) {
// 拿取书籍图片标签
Element imgElement = bookLiElement.getElementsByTag("img").first();
// 根据页面DOM树规则进行处理拿取图片地址
String booksImg = imgElement.attr("data-original");
if (StrUtil.isEmpty(booksImg)) {
booksImg = imgElement.attr("src");
}
booksImg = "https:" + booksImg;
// 拿取书籍标题标签
Element titleParentElement = bookLiElement.getElementsByClass("name").first();
Element titleElement = titleParentElement.getElementsByTag("p").first();
String title = titleElement.text();
// 拿取书籍价格标签
Element priceParentElement = bookLiElement.getElementsByClass("price").first();
Element priceElement = priceParentElement.getElementsByTag("span").first();
String price = priceElement.text();
// 装载进书籍对象中
Books books = Books.builder()
.img(booksImg)
.title(title)
.price(price)
.build();
// 打印查看
System.out.println(books);
}小结
使用爬虫最主要处在于:一是请求网址去拿取网页源码,二是解析网页去拿取所需要的信息。
爬虫作为一种强大的数据收集工具,在各个领域都有着广泛的应用但是使用爬虫时,我们需要遵守相关法律法规和道德规范,确保爬虫技术的合法、合规使用。爬虫使用者应严格遵守Robots协议以及在不侵犯不影响对方权益的情况下合法使用。

爬虫“君子协议”
使用爬虫时通常要遵循Robots协议,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),也称为爬虫协议、爬虫规则等。这个协议的主要目的是告诉搜索引擎哪些页面可以被抓取,哪些页面不能被抓取。Robots协议通常以.txt的形式存在于网站的根目录下面,当爬虫程序向目标网站发起请求时,会遍历到这个文件。
虽然Robots协议为爬虫提供了一套行为准则,但它并不能强制规范抓取工具对网站采取的行为;是否遵循这些命令由抓取工具自行决定。大部分正规的搜索引擎都会遵守这个协议,但也有一些开发者为了抓取内容,可能不会检查robots.txt文件,无意中可能违反了Robots协议。因此,Robots协议更多地是一种道德约束,而非法律强制,它“只约束君子不约束小人”。
网站反爬策略
Robots.txt文件
通过在网站根目录下放置一个robots.txt文件,网站所有者可以指明哪些页面或路径是禁止爬取的。善意爬虫在访问网站时会首先查看这个文件,以了解哪些内容是可以爬取的。
User-Agent检测
每个浏览器或爬虫程序在向服务器发送请求时,都会附带一个User-Agent,这是它们向服务器表明身份的一种方式。网站可以通过检测User-Agent信息,识别出是否为爬虫程序进行访问。对于非正常的User-Agent,可以拒绝其访问或采取其他措施。
IP封锁
通过计算来自同一IP地址的请求频率,从而判断一旦某个IP地址的请求超过设定的阈值,可能就是爬虫在进行恶意请求,服务器可以进行暂时或永久地封锁该IP地址。
使用验证码防御
对于需要登录才能访问的网站,可以通过设置验证码来防止爬虫的自动登录。这种方式可以有效阻止那些没有用户交互能力的自动化爬虫。或在检测到异常请求模式时弹出验证码认证,以确定是人类在进行操作而非自动化爬虫。
数据加密防御
对于敏感信息,可以使用数据加密技术进行保护,以防止被爬虫程序抓取。即使爬虫能够访问到这些数据,也无法读取其实际内容。
使用反爬虫技术
例如设置陷阱,使用JavaScript生成动态页面等,这些都能增加爬虫抓取数据的难度。动态渲染的页面使得爬虫难以解析出实际的内容,因为页面内容是由JavaScript在客户端实时生成的。
访问频率限制
设置同一IP地址在一定时间内的访问频率限制,防止爬虫程序对网站进行过于频繁的访问。这种方式可以有效防止恶意爬虫对网站造成过大的负载。
Cookie反爬虫
服务器可以通过校验请求头中的Cookie值来区分正常用户和爬虫程序。服务器会对每一个访问网页的人给予一个Cookie,而一些简单的爬虫可能并不会处理或响应Cookie。
以上反爬策略通过一些验证限制措施只能在一定程度降低爬虫危害。但是 所谓“道高一尺魔高一丈”,爬虫使用者可能会通过设置代理字段模拟浏览器请求、模拟网页点击、输入JavaScript代码、进行图片验证识别、使用动态IP池等手段去进行数据的爬取,故而没有百分百安全的策略。最全面的方案应为通过上述手段尽量增加爬取者的爬取难度,然后网站运维人员可以通过分析日志去监控是否存在有大量恶意请求IP从而去溯源追寻到恶意请求者。




